From One Server to Thousands: A Guide to Scaling and Load Balancers
When you launch a new application, a single-server architecture is usually more than enough.
Your users send requests, the server processes the backend logic, talks to the database, and returns a response. For early-stage projects or low-traffic MVPs, this setup works perfectly.
But successful applications rarely stay static. As more concurrent users start using your product, the sheer volume of requests increases. At some point, the server reaches its physical resource limits, and simply writing cleaner code or optimizing queries is no longer enough.
To keep your application responsive under heavy traffic, you need to scale.
Every Server Has a Hardware Limit

To understand why a single server fails under load, think of it like a one-person fast-food drive-thru. The lone employee has to take the order, cook the food, bag it, and process the payment. If only a few cars show up an hour, the workflow is seamless.
But what happens when hundreds of cars arrive simultaneously? The queue wraps around the block, customers face long wait times, and people eventually leave out of frustration.
In the digital world, a single server faces the exact same physical constraints. Every request your application handles consumes a finite slice of infrastructure hardware:
CPU: Brainpower required to execute application logic and serialize data.
RAM: Execution memory needed to hold state and application contexts during runtime.
Network Bandwidth: The throughput capacity required to handle concurrent incoming and outgoing packets.
Disk I/O: The speed at which your application reads from or writes to persistent storage.
When traffic spikes, these physical resources hit 100% utilization. As a result, requests pile up in the network stack, response times degrade, and users experience timeouts or explicit HTTP errors. This failure isn't due to bad code—it's a fundamental hardware limitation.
Scaling: Vertical vs. Horizontal
When a single server hits its ceiling, you have to increase your infrastructure's capacity. This is known as scaling, and there are two primary pathways to achieve it.
1. Vertical Scaling (Scaling Up)
In our drive-thru analogy, vertical scaling is like replacing your lone employee with a world-class super-chef.
[ 4 CPU, 8 GB RAM ] ───( Upgrade Instance Type )───> [ 16 CPU, 64 GB RAM ]
You keep your single-server setup but upgrade the underlying hardware through your cloud provider—adding more CPU cores, expanding RAM, or moving to faster storage.
While this requires zero changes to your application architecture, it creates a Single Point of Failure. If that single machine crashes, your entire app goes offline. Furthermore, you will eventually hit a hard physical ceiling—the largest instance type your cloud provider offers—where further upgrades become prohibitively expensive.
2. Horizontal Scaling (Scaling Out)
Instead of making one server larger, horizontal scaling is like opening three more drive-thru lanes and hiring three more employees.

You deploy identical copies of your application across multiple, independent servers to share the workload. This builds redundancy into your system; if Server 1 suffers a hardware failure, Server 2 and Server 3 continue handling requests. This approach offers near-infinite scalability and is the blueprint for modern web infrastructure.
Comparison Between Horizontal and Vertical Scaling

More Servers Create a Routing Problem
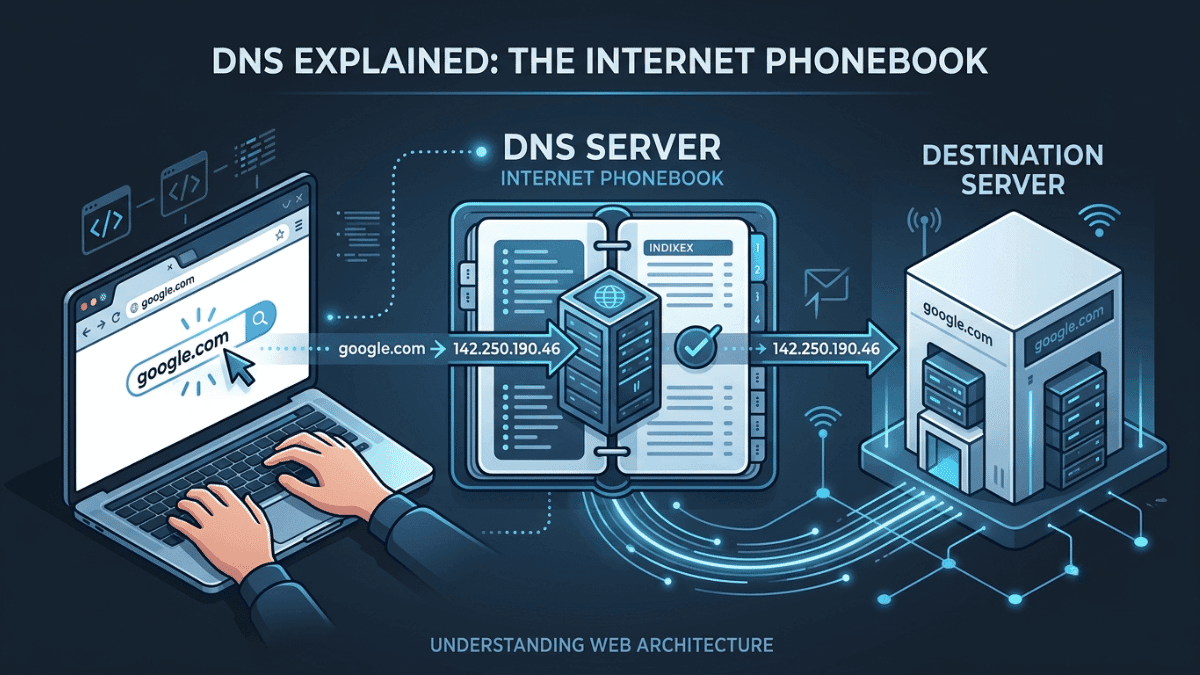
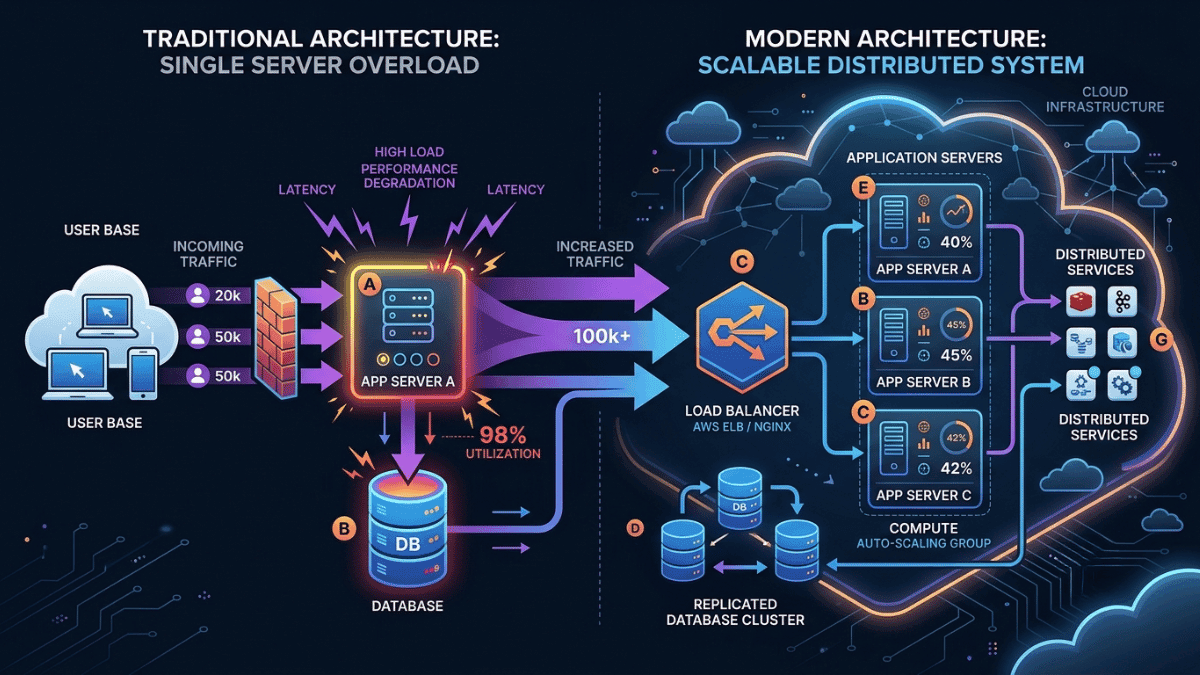
While horizontal scaling solves the capacity issue, it introduces an immediate architectural challenge. Imagine your application is now running across four separate servers. A user types your URL into their browser. Which backend server should handle that specific request? The browser doesn’t know. While DNS maps a domain name to an IP address, basic DNS isn't dynamic enough to distribute traffic evenly based on real-time server loads. To bridge this gap, you need a dedicated traffic coordinator. This is where Load Balancers come in.
What Is a Load Balancer?
A Load Balancer acts as a traffic manager that sits directly in front of your server pool, serving as the singular public entry point for all incoming traffic.
Instead of clients communicating directly with individual application instances, every request hits the load balancer first. It evaluates the current state of your backend cluster and routes the request to the optimal server.

To the end-user, the architecture is entirely invisible. They interact with a single domain, while behind the scenes, the load balancer prevents any single server from becoming a bottleneck.
How the Load Balancer Distributes Traffic

Load balancers rely on specific routing strategies, or algorithms, to distribute requests efficiently:
Round Robin: The simplest method. Requests are handed out sequentially across the pool (Server 1, then Server 2, then Server 3) in a continuous loop.
Least Connections: A dynamic approach. The load balancer tracks active connections and automatically directs new traffic to the server currently handling the lightest workload.
Health Checks: The load balancer continuously monitors your backend instances via automated ping requests. If a server stops responding or throws errors, the load balancer instantly pulls it from the pool, preventing users from experiencing broken pages.
Conclusion
Most applications don't need a multi-server distributed architecture on day one. Introducing load balancing too early simply adds unnecessary operational complexity.
Good engineering is about choosing the simplest architecture that satisfies your current requirements while keeping a clear path for future expansion. Once your application layer genuinely outgrows a single machine, a load balancer paired with a horizontally scaled cluster is your definitive next step.