Building Reliable LLM Systems: From API Calls to Distributed Systems

Traditional software is predictable. You type something in, and you get the exact same result out every single time. Your database works, your code runs, and everything behaves.
But the moment you add an AI model (like an LLM) to your app, that predictability breaks. You aren't calling a standard piece of code anymore; you are dealing with a system that guesses the next word.
That changes how you have to build your software.
The Big Shift: "Using AI" vs. "Engineering AI Systems"
When most developers start out, they just make a simple API call:
response = llm.generate(prompt)
It looks like a normal function, but in the real world, LLMs behave like a messy external service. At scale, they bring a lot of headaches:
They freeze or time out: Responses can take seconds or fail entirely.
They break rules: They make things up (hallucinate) or send back bad data formats.
They get expensive: High traffic can lead to massive, unexpected bills.
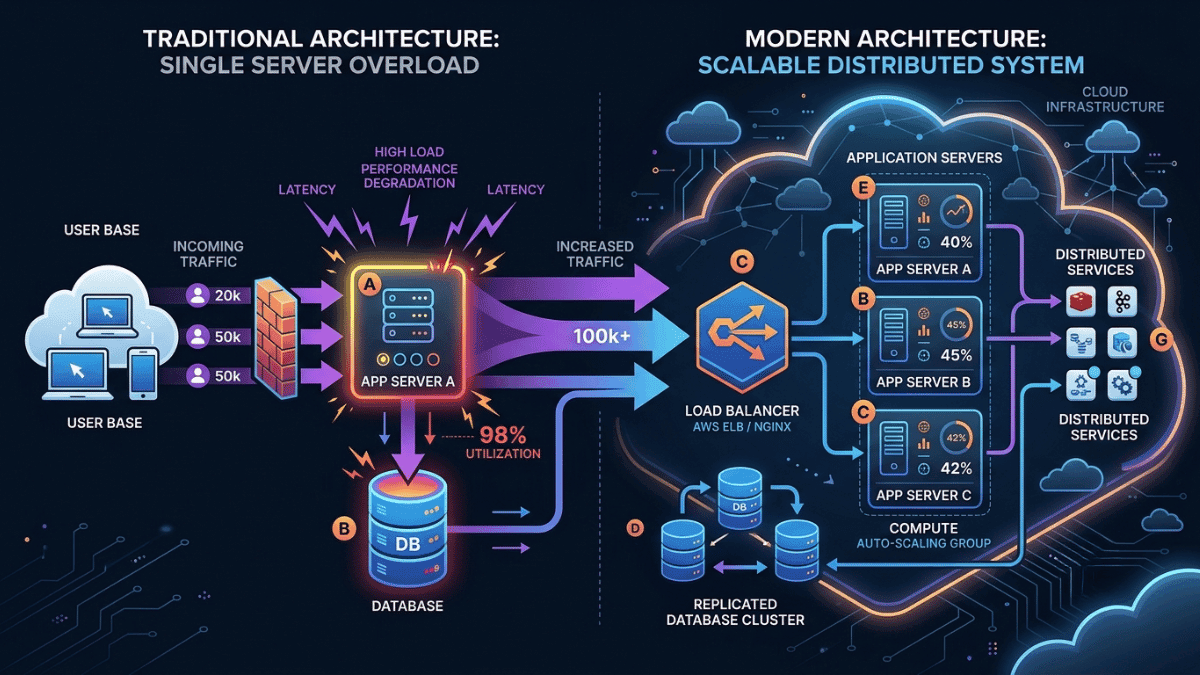
Moving from a basic demo to a real product means you have to stop treating AI like a simple function and start treating it like unpredictable infrastructure.
How LLMs Compare to Traditional Software
Because AI models are unpredictable, you have to build your system assuming they will fail.
Here is how standard tech compares to AI tech:
| Feature | Standard API | AI Model (LLM) |
|---|---|---|
| Results | Same every time | Changes slightly every time |
| Output Type | Clean, structured data | Raw text or messy data |
| Speed | Fast and predictable | Slow and random |
| Testing | Easy (Right vs. Wrong) | Hard (Needs grading) |
How to Fix "Retry Storms"
When an LLM takes too long, a basic app will immediately try calling it again. If that fails, it tries again.
Before you know it, one user request turns into dozens of automatic retries:
1 Request → 3 Retries → 9 Retries → 27 Retries
If thousands of users are on your app, your system will accidentally flood the AI provider with traffic. This makes the outage worse and gets your account blocked.
The Fix: Wait and Stagger
Instead of retrying immediately, smart systems do two things:
Back off: Wait a bit longer between each try (like 1 second, then 2 seconds, then 4 seconds).
Add Jitter (Randomness): Don't let every computer retry at the exact same second. Make them wait a random amount of time (like 3.2 seconds or 4.5 seconds). This spreads out the traffic so your servers don't crash all at once.
Why You Need Message Queues
In a basic app, a user clicks a button and waits on the screen while the AI thinks. If the AI is slow, the whole app grinds to a halt.
To fix this, companies use Message Queues (like Amazon SQS or RabbitMQ). Think of it like a waiting line at a fast-food restaurant:
User Request → Waiting Line (Queue) → Workers → AI Processes It → Saved to Database
Instead of making the user stare at a loading spinner, the app takes the request, puts it in line, and lets background workers handle the AI processing. This protects your app from crashing when traffic spikes.
Real-Time vs. Batch: When to Use Which
You don't need to run every single AI task instantly. Splitting your tasks saves money and keeps your app fast.
Real-Time AI
Best for: Chatbots, live helpers, typing assistants.
The Catch: It’s hard to keep fast, and expensive when a lot of people use it at once.
Batch AI (In Groups)
Best for: Summarizing long files overnight, sorting data, creating search tags.
The Benefit: It’s way cheaper, handles errors gracefully, and runs when your servers are quiet.
The Core Problem: Speed vs. Quality vs. Cost
With normal code, making it faster doesn't make it more expensive. With AI, everything is connected in a three-way balancing act:
$$\text{Speed} \longleftrightarrow \text{Quality} \longleftrightarrow \text{Cost}$$
If you want better quality, you need a bigger model, which is slower and costs more.
If you want it cheaper, you use a smaller model, but the quality drops.
If your app slows down by even half a second, requests pile up, your servers work harder, and your bill goes up.
Testing and Monitoring AI Is Way Harder
If a normal app breaks, it usually throws a clear error code (like 404 Not Found).
An AI app can look like it worked perfectly, give you a successful code, but send back completely wrong information or broken text.
Watching the App
You can't just check if your servers are turned on. You have to track:
Which version of the prompt you used.
How many words (tokens) the AI spent.
How often the AI sends back broken data.
Testing the Code
You can't use simple math tests anymore. You can't write a test that says 2 + 2 must equal 4. Instead, you have to write tests that check if the answer "looks reasonable." Dealing with these gray areas is the hardest part of building with AI today.
Conclusion
The hardest part of building an AI company isn't writing a clever prompt or picking the best model.
The real challenge is building a stable system that doesn't crash when the AI gets slow, expensive, or weird. The future belongs to engineers who can build reliable apps using unpredictable tools.